“정산파일 자동화”를 하려다, 규칙과 검증을 다시 설계하다
AI 챔피언 10번째 이야기 — 매출관리팀 강희성님
AI 챔피언 10번째 이야기 — 매출관리팀 강희성 님
재무·정산 업무는 많은 검증 과정을 거쳐 숫자의 정합성을 맞추는 것이 중요합니다. 다만 그 정합성을 확인하고 설명하는 과정에는, 경우에 따라 많은 시간이 소요되곤 합니다.
파트너마다 정해진 정산 기준이 있었지만, 이를 다시 검증하려면 매번 파일을 거슬러 올라가야 했습니다.
정산 결과를 재확인하거나 설명해야 할 때마다 어떤 파일을 기준으로 계산됐는지, 어떤 값이 어떤 방식으로 반영됐는지를
다시 추적하는 과정이 반복됐습니다.
매출관리팀 강희성님이 맡고 있던 별도정산 업무는 이런 구조적 문제가 가장 집중적으로 드러나는 영역이었습니다.
대부분은 이미 내부DB로, 문제는 ‘소수의 별도정산’이었다
모든 거래가 이런 방식이었던 것은 아닙니다. 대부분의 거래처는 이미 자사 데이터 구조에 맞는 형태로 정산이 이루어지고 있었고, 그 결과는 시스템 안에서 자연스럽게 데이터로 관리되고 있었습니다.
문제는 소수의 거래처였습니다.
거래 구조나 파트너 시스템 특성상, 자사 데이터 구조에 그대로 맞추기 어려운 경우들이 있었고 이들은 불가피하게 별도정산 파일 기반의 업무로 운영되고 있었습니다.
이 영역은 규모로 보면 크지 않았지만, 매번 정산 결과를 다시 확인하거나 설명하려고 하면 파일을 다시 하나씩 열어보며 맥락을 복원해야 했습니다.
희성님이 문제로 느낀 지점은 바로 여기였습니다. 맞춰진 결과를 연결된 데이터로 남기지 못하고 있다는 점이었습니다.
“표준화”가 아니라 “DB화에 필요한 최소 정보”부터
목표는 파트너의 정산파일 양식을 하나로 통일하는 것이 아니었습니다. 그건 현실적으로도 어렵고, 이 문제의 해법도 아니었습니다.
대신 방향을 이렇게 잡았습니다. 각기 다른 정산파일에서 정산과 트래킹에 필요한 최소한의 정보만 선별해 내부 DB 구조로 끌어온다는 접근이었습니다.
여기서 말하는 최소 정보는 정산파일을 그대로 재현하기 위한 항목이 아니라, 정산 결과를 설명하고 다시 추적할 수 있게 해주는 값들이었습니다.
정산 기준이 되는 금액, 파트너를 식별할 수 있는 기준값, 거래를 연결할 수 있는 참조 정보, 그리고 상태나 통화처럼 이후 계산과 검증에 영향을 주는 요소들이 여기에 포함됐습니다.
이 작업의 핵심은 파일로만 존재하던 정산 정보를 내부 DB 구조 안으로 옮기는 것이었습니다.
첫 구현: Apps Script
초기 구현은 Google Apps Script로 진행됐습니다.
정산파일을 읽어 필요한 값을 추출하고, 이를 하나의 표준 템플릿 형태로 변환하는 방식이었습니다. 작게 시작했을 때는 빠르게 결과를 확인할 수 있었고, 실제 업무에도 적용할 수 있었습니다.
하지만 기쁨도 잠시, 별도정산 대상 거래처가 늘어나면서 한계가 드러났습니다.
단일 스크립트 안에 모든 파트너의 규칙을 담다 보니 파트너마다 다른 정산 기준과 파일 구조가 조건문으로 계속 추가됐고, 한 규칙을 수정하면 다른 결과에 영향을 주는 상황이 반복됐습니다.
이 구조에서는 정산파일이 늘어날수록 관리 비용도 함께 커질 수밖에 없었습니다.

규칙을 코드에서 떼어내고, 파이프라인으로 만들다
희성님은 기존 방식을 과감히 버리는 결정을 내렸습니다. 구조 자체를 다시 만들기로 한 거죠.
출발점은 규칙과 실행 로직을 분리하는 것이었습니다.
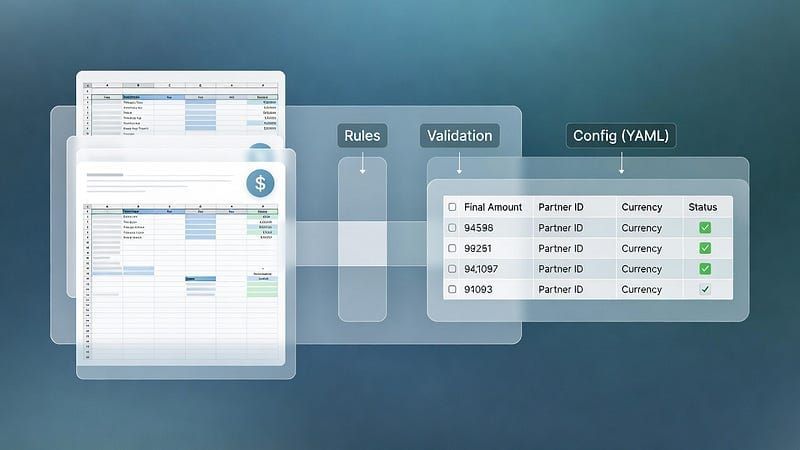
파트너별 정산파일 처리 규칙을 코드 안에 직접 작성하는 대신, 각 파트너의 규칙을 YAML 파일 단위로 관리하도록 구조를 바꿨습니다. 이 규칙에는 단순한 컬럼 매핑뿐 아니라, 파일마다 의미가 다른 항목을 어떻게 해석할지, 상태값에 따라 어떤 처리를 해야 하는지 같은 기준이 함께 담겼습니다.
공통 실행 로직은 하나의 파이프라인으로 유지하고, 변화가 필요한 부분은 설정 단위로 분리해 관리했습니다. 정산 규칙이 늘어나더라도 코드를 복잡하게 만들지 않고, 변경 범위를 설정 단위로 통제하기 위한 구조입니다.
이 구조는 Config-driven ETL에 가깝습니다.
즉, 실행 로직은 그대로 두고 파트너마다 다른 정산 기준만 설정으로 분리해 관리하는 방식입니다.
정산파일을 수집하고, 파트너별 규칙을 적용해 데이터를 추출한 뒤 정합성을 검증하고, 검증 근거가 함께 남도록 내부 표준 템플릿으로 결과를 저장합니다.
이 방식 덕분에 소수의 별도정산 거래처에서 발생하던 파일 기반 업무도 기존 내부 DB 구조 안으로 자연스럽게 편입될 수 있었습니다.

결과보다 중요한 것: 검증과 트래킹
이 구조에서 가장 중요하게 다뤄진 부분은 검증이었습니다. 왜 이 결과가 나왔는지를 다시 설명할 수 있어야 했기 때문입니다. 그래서 결과와 함께 행 수, 금액 합계, 기준값 차이를 자동으로 확인하고, 이상 지점이 있으면 바로 드러나도록 설계했습니다.
이제는 정산파일을 하나하나 다시 열어보지 않아도, 내부 DB에 쌓인 데이터를 기준으로 정산 결과를 추적하고 설명할 수 있는 상태가 되었습니다.
소수의 예외를 구조 안으로 가져오다
이번 작업의 의미는 별도정산 업무를 자동화했다는 데만 있지 않습니다.
이미 DB화되어 있던 대부분의 거래 구조 옆에, 파일 기반으로 남아 있던 소수의 예외 영역을 같은 내부 데이터 구조 안으로 가져왔다는 점에 있습니다.
그 결과, 정산 결과를 맞추는 데서 끝나지 않고, 근거까지 바로 추적·설명할 수 있는 데이터 구조로 바뀌었습니다..
이 작업이 남긴 것은 단순 자동화가 아닙니다. 정산파일 기반 업무를 내부 데이터 구조로 내재화하기 위해 규칙과 검증을 설계한 경험이었습니다.



