Product Engineer: 하루 500건 분석 요청을 받아내는 데이터 에이전트, 일을 돕는 AI에서 일을 수행하는 AI로
PEPE 세션 — 데이터 엔지니어링팀 정현영 님

마이리얼트립 데이터 에이전트가 슬랙에 라이브된 지 일주일도 채 안 된 시점, 이미 들어온 분석 요청은 2,000건을 넘기고 있었습니다. 이번 PEPE 세션에서 프로덕트 엔지니어(PE) 정현영님은 “하루에 500건 분석 요청을 받아내는 AI Agent 만드는 법”을 소개했습니다.
데이터 에이전트가 라이브되기 전까지는, “어제 거래가 얼마야”라는 질문을 처리하던 사람은 분석가였습니다. 분석가 한 명이 하루에 처리할 수 있는 요청은 많아야 4건에서 7건. 이제는 마이리얼트립 구성원 누구나 슬랙에서 데이터 에이전트를 태그하고 어제 숙박 거래액을, 그것도 취소분 제외하고 전주 대비를 추가해서 엑셀로 받아볼 수 있습니다. 라이브 직후의 어떤 날에는 하루에 500건에서 600건의 분석 요청이 처리됐습니다.
핵심은 처리량의 숫자가 아닙니다. 분석가들이 더 본질적인 일에 집중할 수 있게 됐다는 것이 현영님이 강조하는 변화입니다. 반복적인 분석 요청은 에이전트가 받고, 사람은 지표를 새로 설계하거나 정책 의사결정을 하거나 또 다른 AI 에이전트를 만드는 일에 시간을 씁니다. 그렇다면 그 에이전트는 어떻게 만들어졌을까요. 현영님은 두 축으로 정리해 설명을 시작했습니다.

도구가 아니라 동료를 만들고 싶었다
처음 만든 봇은 그럴듯한 답변을 했습니다. 다만 회사 기준과 어긋났습니다. 같은 “거래액”이라도 어떤 테이블의 어떤 컬럼을 기준으로 뽑느냐, 취소분을 포함하느냐 마느냐에 따라 숫자가 달라지는데, 초기 봇은 그 정의를 명확하게 알지 못한 채 매번 다른 답을 내놨습니다.
“거래 뽑아줘 라고 얘기를 하면, 거래액이라는 게 정확히 무엇인가라는 것을 에이전트가 아주 명확하게 알지 못하기 때문에 실수를 좀 연발하고 그랬어요.”
당연한 결과였습니다. 더 잘 설계해야 했습니다. 현영님이 만들고 싶었던 것은 “내 일을 빠르게 도와주는 도구”가 아니라, 통제를 통째로 맡길 수 있는 수준의 AI 동료였습니다.
“내가 뭔가를 빠르게 할 수 있다, 잘 할 수 있다 이 정도가 아니라, 이 일은 아예 통제를 얘한테 맡기겠다 하는 수준의 AI를 만들려고 했습니다.”
이 목표를 위해 현영님은 두 축을 잡았습니다.
하나는 하니스(Harness) — 에이전트에게 어떻게 움직일지 알려주는 장치입니다. 워크플로, 권한, 안전망이 여기에 들어갑니다.
다른 하나는 지식 체계 — 거래액은 어떻게 구하고, 어떤 테이블이 어떤 용도인지 정의해 두는 사전입니다. 이 둘이 결합돼야 LLM의 비결정성을 누르고, 매번 같은 질문에 같은 형태로 답할 수 있는 에이전트가 나옵니다.

슬랙 메시지 한 통이 답이 되기까지
데이터 에이전트는 슬랙에서 메시지가 들어오는 순간 여러 단계를 거쳐 동작합니다. 현영님은 발표에서 이 흐름을 단계별로 풀어 설명했습니다.

가장 앞단에는 Listener가 있습니다. 서버에 파이썬 코드 하나가 상시로 떠 있으면서 슬랙 이벤트를 감지합니다. 메시지가 들어오면 입구만 담당하고 바로 다음 단계로 넘깁니다.
다음은 Dispatcher입니다. 슬랙 데이터 에이전트 채널에는 사람들끼리 대화하는 메시지도 들어오고, 같은 질문이 두 번 들어오기도 하고, 광고 카피를 만들어 달라거나 검색을 해달라는 엉뚱한 요청도 들어옵니다. Dispatcher는 잡담과 분석 요청을 분류하고, 중복 요청을 거르고, 스레드 단위의 세션을 관리하는 역할을 동시에 맡습니다. 가벼운 모델로 충분히 처리할 수 있는 일이라 비용 절감을 노렸는데, 처음에 시도한 Haiku는 thinking이 약해 분류 품질이 받쳐 주지 못했습니다. 결국 Sonnet으로 옮겼고, Opus 대비 1/8에서 1/10 수준의 토큰만 쓰면서도 분류 정확도는 안정적이었습니다.
Dispatcher를 통과한 요청은 Parent Worker로 넘어갑니다. 이름은 워커지만 개념적으로는 오케스트레이터에 가깝습니다. 요청 자체를 처리하지는 않고, 전체 세션의 맥락을 잡고 작업을 어디로 보낼지 결정합니다.
실제 작업을 하는 것은 Sub-agent(워커)들입니다. 간단한 분석을 빠르게 처리하는 워커, 복잡한 분석에 특화된 워커, 검색 워커, 보고서 워커, 시각화 워커, 구글 시트 워커가 따로 있습니다. 워커마다 권한도 다르고 룰도 다릅니다. 큰 모델 하나가 모든 일을 떠안는 대신, 특화된 워커들이 분업합니다.
이 모든 워커가 도는 곳은 하나의 클러스터입니다. 여러 개의 Claude Code Max 계정을 Docker 가상 환경 위에 띄워 두고, 들어오는 요청을 활성 워커들이 차례로 받아갑니다. 슬랙에서 “데이터 에이전트”를 태그하면 답변에 번호가 붙은 이모지가 달리는데, 이 번호가 바로 클러스터의 어떤 워커가 그 분석 요청을 맡았는지를 의미합니다.
비용 측면에서 현영님은 한 가지 팁을 공유했습니다. 이런 에이전트를 API 키로 운영하면 가격이 훨씬 비싸진다는 것이었습니다. 대신 Claude Setup Token이라는, 사내 운영을 위해 안내된 방식이 있고, 헤드리스 모드와 결합하면 훨씬 적은 비용으로 클러스터를 운영할 수 있습니다.
왜 서브 에이전트로 쪼갰을까: Lazy Load의 발견
특화된 워커로 쪼갠 이유는 단순히 일을 잘하기 위해서만이 아닙니다. 컨텍스트 비용 때문에 안 쪼갤 수가 없었다는 쪽이 더 정확합니다.
현영님이 직접 측정해 본 결과, Parent Worker가 모든 룰을 끌어안고 동작하면 세션당 230K 토큰이 그냥 사라졌습니다. 데이터 파이프라인의 메타데이터, Metric Registry, 행동 규칙, 워커별 권한 명세까지 다 머리에 넣고 시작하면 질문 몇 개 받기도 전에 모델이 죽거나 일주일치 사용량이 순식간에 소진됩니다.
문제를 더 까다롭게 만드는 것은 헤드리스 모드의 동작 방식입니다. 일반적인 클로드 사용은 한 세션 안에서 대화가 이어지지만, 슬랙 위에서 도는 에이전트는 메시지가 올 때마다 새로운 세션이 떠야 합니다. 이전 대화의 로그를 먹고 시작하기 때문에, 가장 위에 떠 있는 Parent Worker는 매번 새롭게 컨텍스트를 주입받습니다.
“매번 새롭게 세션이 뜨는 구조에서, Parent Worker가 가진 룰은 매번 새로 주입될 수밖에 없는 구조입니다. 거기를 최소한으로 가볍게 가져가야 합니다.”
해법은 Lazy Load였습니다. Parent Worker는 룰의 본문을 들고 있지 않고, “이런 작업이 들어오면 어떤 서브 에이전트를 띄워라” 하는 주소값만 갖고 있습니다. 실제 룰은 워커가 자기 작업에 필요한 만큼만 그때그때 로드합니다.
“거기는 룰도 다 박아놓지 않고, 어떤 룰은 어디에 있어 라는 링크 형태로 적어놨어요. 그런 식으로 만드는 게 핵심입니다.”

이 구조는 부수 효과까지 챙겨 줬습니다. 워커마다 권한이 분리되니 보고서 워커가 BigQuery를 직접 만지는 일이 차단됐고, 워커별 작업 명세가 작아지니 한 부분만 빠르게 고칠 수 있어 유지보수가 쉬워졌습니다.
Metric Registry: 거래액의 법전을 만들었다
지식 체계의 첫 단추는 DBT YAML 메타데이터였습니다. 현영님이 입사 후 첫 두 달 동안 가장 공들여 한 일이 바로 이것이었습니다. 마트 테이블 하나하나에 어떤 컬럼이 어떤 의미를 갖는지를 야물 파일로 적어 두는 작업입니다.
다만 메타데이터만으로는 부족했습니다. 같은 금액 컬럼이 거래액인지 매출인지, 마트 테이블이 여러 개일 때 어느 것을 기준으로 잡아야 하는지, 거래액을 뽑을 때 취소분은 빼야 하는지 등은 컬럼 설명만으로 풀리지 않습니다. 사람들 사이에서도 합의가 필요한 영역입니다.
그래서 도입한 것이 Metric Registry입니다. 회사에서 자주 쓰이는 핵심 지표를 YAML 묶음으로 모아 두고, 표현·정의·필터·계산식을 한 곳에서 관리합니다.
“메트릭 레지스트리는 사전처럼, 정확하게는 이건 이렇게 해야 합니다 라고 법을 만들어 놓은 형태예요.”
GMV_total 같은 메트릭은 다음과 비슷한 형태로 정의됩니다.
- id: gmv_total description: 총거래액 (Gross Merchandise Value) keywords: ["GMV", "거래", "총거래"] kind: sum expression: SUM(<payment_amount>) notes: 기본은 결제 거래액 기준. 취소분 반영 여부는 요청 맥락에 따라 분기.
키워드는 사용자의 자연어 요청과 매칭하기 위한 단서입니다. “거래 얼마야”라고 묻든 “GMV 뽑아줘”라고 묻든 “총거래액”이라고 묻든, 워커는 먼저 Metric Registry에서 키워드를 훑어 같은 메트릭으로 수렴시킵니다. kind와 expression은 어떤 SQL을 만들어야 하는지에 대한 정의입니다. 표현이 달라도 결정론적으로 같은 산식에 도달하게 만드는 것이 Registry의 핵심입니다.
행동 규칙의 우선순위도 워크플로로 명시돼 있습니다. Metric Registry를 먼저 본다 → 없으면 DBT 메타데이터를 탐색한다 → 그래도 없으면 직접 쿼리로 탐험한다. 자주 쓰이는 지표는 현영님이 직접 Registry에 추가하기 때문에, 데이터 파이프라인이 개선되면 Registry도 함께 업데이트됩니다. 공헌이익 산식이 바뀌는 큰 배포가 예정돼 있다면, Registry 한 줄을 고치는 것으로 에이전트의 답변 방식 전체가 바뀝니다.
지식의 형태에 대해서도 현영님은 분명한 선을 그었습니다. 클로드의 Auto Memory 기능은 끄고, Metric Registry · rules · skills · DBT YAML 같은 명시적 Knowledge만 사용합니다. 무엇을 기억하고 있는지 불투명한 메모리는 검증도 관리도 어렵기 때문입니다. 답변이 어떤 근거로 나왔는지 매번 코드 한 줄까지 거슬러 올라갈 수 있어야, 회사 기준에서 어긋나는 숫자를 미연에 막을 수 있습니다.

지식 체계는 여기서 끝이 아닙니다. Parent Worker는 요청을 받을 때마다 6개 컴포넌트로 정리합니다. 이 요청은 누가 했고, 어떤 범위를 보려는 거고, 어떤 개념을 묻는 것이고, 취소분은 포함인지 제외인지, 합의된 사실은 무엇인지 등이 모두 채워져야 합니다. 이 컨텍스트 팩이 비어 있으면 워커는 작업을 시작하지 않고 사용자에게 되묻습니다.
“숙박만 뽑아요, 아니면 티엠에만 뽑아요? 이 리셀 마켓은 제외하고 뽑아요, 포함하고 싶은 거예요? 이런 식으로 꼼꼼하게 따져 묻습니다.”
엉뚱한 답을 만들어 내느니, 한 번 더 확인하고 정확하게 답하는 쪽을 택한 설계입니다.
안전망 4겹: Role, Gate, Rule, Hook
지식 체계가 답의 정확성을 책임진다면, 안전망은 부작용을 책임집니다. 현영님은 이 부분을 단일 장치가 아닌 4겹의 레이어로 설계했습니다.
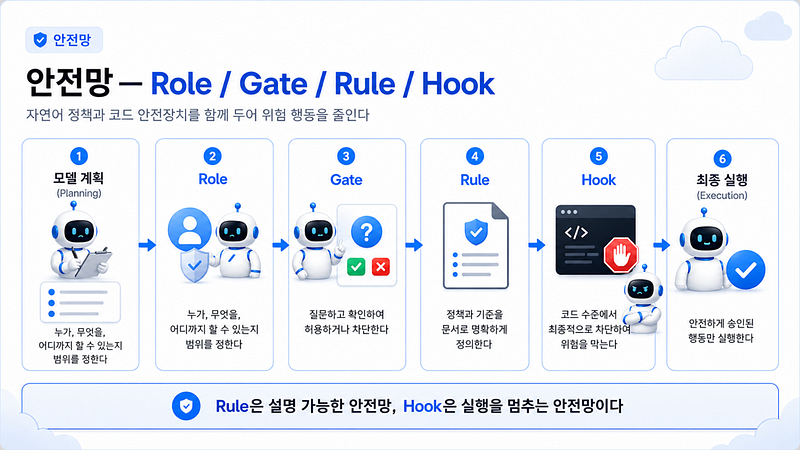
- Role — 권한 범위 제한. 워커마다 할 수 있는 일이 다릅니다. 보고서 워커는 BigQuery를 직접 만지지 못하고, 분석 워커는 컨플루언스에 글을 쓰지 못합니다. 권한이 분리돼 있으니 한 워커가 잘못 동작해도 영향 반경이 그 워커 안에 갇힙니다.
- Gate — 요청 범위 사전 판정. Parent Worker가 들어온 요청을 6개 컴포넌트로 정리하다가 정보가 비어 있다고 판단하면, 워커를 띄우지 않고 사용자에게 되묻습니다. 잘못된 가정으로 잘못된 답을 내느니, 한 번 더 확인하고 정확하게 답하는 쪽을 택한 게이트입니다.
- Rule — 자연어 정책. Metric Registry의 행동 규칙, 워커별 작업 명세, 거래액 산출 우선순위 같은 것들이 여기에 들어갑니다. 사람이 읽고 고칠 수 있는 형태로 적혀 있어 설명 가능한 안전망입니다.
- Hook — 실행 직전 코드 차단. 룰이 설명 가능한 안전망이라면, 훅은 실행을 멈추는 안전망입니다. 워커가 만들어 낸 SQL이 BigQuery로 떠나기 직전, 스크립트가 마지막으로 한 번 더 들여다봅니다.
훅에는 구체적인 규칙이 들어 있습니다. 읽기 전용 쿼리만 허용되고 데이터를 변경하는 명령은 차단됩니다. 모든 쿼리에 스캔 한도 정책이 걸려 있어 비싼 풀스캔이 발생하던 일을 막습니다. 개인정보가 포함된 컬럼은 자동으로 마스킹되어 결과로 나갑니다. “어제 거래”라는 자연어 요청도 결국 파티션 한정·읽기 전용·마스킹 적용된 쿼리로만 떠납니다.
“Rule이 설명 가능한 안전망이라면, Hook은 실행을 멈추는 안전망이에요. 둘 다 필요합니다.”
안전망이 일관되게 적용되도록, 데이터 에이전트는 슬랙 진입점 하나로만 운영합니다. 같은 4겹이 모든 요청에 동일하게 걸리는 구조를 만드는 것이 안전망 설계의 마지막 약속이었습니다.
100개의 eval로 품질을 고정한다
기능을 한 번 잘 만든 것과, 그 기능이 다음 배포에서도 살아남는 것은 다른 문제입니다. AI 에이전트는 새로운 기능을 추가하면 기존에 잘 동작하던 다른 길이 갑자기 어긋나기 시작합니다.
“구글 시트 만들어 주는 기능을 추가했는데, 갑자기 엑셀 보고서 만들어 달라고 해도 구글 시트를 만들어 주면 안 되잖아요.”
이런 문제를 막기 위해 현영님은 100개가 넘는 shell test와 eval을 운영하고 있습니다. 각각은 “이런 프롬프트가 들어오면 이런 동작을 해야 한다”는 기대값을 명시적으로 정의해 두고, 매 배포 전에 실제 슬랙 대화를 자동 재현해 4가지 축을 검증합니다 — 정확성, 행동 경로, 안정성, 형식. 답이 맞는지뿐만 아니라, 어떤 워커를 거쳐 어떤 룰을 참조했는지, 같은 요청에 같은 답을 주는지, 출력 포맷이 약속한 형태(엑셀이면 엑셀, 구글 시트면 구글 시트)로 나가는지를 함께 봅니다.

신뢰는 prompt 수정으로 만들어지지 않습니다. 한 곳을 고치면 다른 데서 회귀가 나기 때문입니다. 그래서 현영님은 운영 루프 자체를 코드 안에 고정해 뒀습니다 — 실패 사례 기록 → 원인 분석 → Knowledge 수정(Metric Registry / rule / skill) → 재발 방지 test 추가. 사용자가 “이거 이상해요”라고 한 건이 들어올 때마다 그 케이스가 새로운 eval로 등록됩니다. 운영을 통해 룰북이 점점 두꺼워지는 구조입니다.
“그렇지 않으면 기능이 많아질 때 반드시 이상한 행동을 할 수밖에 없습니다.”
eval은 화려한 기능이 아닙니다. 다만 에이전트의 품질을 사람의 감에 의존하지 않게 만드는 가장 단단한 장치입니다.
워커가 죽으면 대기조가 들어온다
클러스터의 워커 중 일부는 평소에 일을 하지 않고 대기합니다.
이런 구조가 필요한 이유는 사용 패턴 때문이었습니다. 한 사용자에게 요청이 몰리는 시간대가 있고, 그러면 그 흐름을 받던 워커가 다른 워커들보다 빨리 5시간 리밋이나 주간 리밋에 걸립니다. 처음에는 현영님도 사용자에게 “워커가 죽었으니 새 스레드 파세요”라고 안내했지만, 그 방식으로는 분석 흐름이 매번 끊어졌습니다.
지금은 자동 선수 교체가 작동합니다. 워커가 리밋에 걸려 API 호출 단계에서 에러를 뱉으면, Dispatcher가 그 에러를 잡아 대기 중이던 예비 워커에게 즉시 그 자리를 넘깁니다. 사용자가 의식하기 전에 새 워커가 분석 흐름을 이어받습니다.
“백업이 대기하던 선수가 벤치에 앉아 있다가 뛰어나오는 거죠. 쟤 죽었어 하면서 선수교체하면서 들어옵니다.”
작은 디테일이지만, 에이전트를 도구가 아니라 동료로 만들겠다는 처음의 약속이 여기서도 이어집니다. 사람이 매번 백업 절차를 안내해야 한다면, 그건 동료라기보다 손이 많이 가는 도구에 더 가깝습니다.
Closure-loop: 사람이 빠지는 게 나은 루프도 있다
현영님은 마무리에서 Closure-loop이라는 개념을 꺼냈습니다. 요즘 자주 회자되는 Human-in-the-loop의 반대축에 있는 개념입니다. AI가 도는 흐름에 사람이 들어가서 매 단계 피드백을 주는 구조가 Human-in-the-loop이라면, Closure-loop은 어떤 루프는 사람이 빠지는 게 더 낫다고 말합니다. 사람이 병목이라면, 그 자리에서는 사람이 비키는 쪽이 더 좋은 결과를 낳기 때문입니다.
“여태까지 반복되는 워크플로우 같은 것들은 AI에게 충분히 다 넘길 수 있다고 생각했고, 다를 수 있는 루프가 있지 않을까 라고 봤습니다.”
마이리얼트립 분석가들이 데이터 에이전트로 옮긴 것은 정확히 이 부분입니다. 반복되는 분석 자동화는 에이전트에게 넘기고, 사람은 지표 자체를 새로 설계하거나, 정책 의사결정을 하거나, 또 다른 AI 에이전트를 만드는 일에 시간을 씁니다. 데이터 파이프라인에 새로운 데이터가 들어오면 Metric Registry를 업데이트하고, 새로운 사용 사례가 나오면 eval을 추가하고, 워커의 행동 규칙을 다듬습니다.
정현영님이 마지막에 남긴 메시지는 에이전트를 만드는 일이 특정 직무에 묶여 있을 필요가 없다는 것이었습니다. 자기 업무에 반복 워크플로가 있다면, CRM 발송, 영업 데이터 정리, 재무 리포트 어디든 닫힌 루프로 만들 수 있는 영역이 있습니다.
마이리얼트립이 모든 엔지니어를 PE — 문제를 정의하는 순간부터 결과까지 책임지는 사람 — 로 정의해 온 흐름과도 닿아 있는 메시지입니다.
“비개발자 분들도 굉장히 많이 시도해 볼 수 있고, 내 업무를 아웃소스 하기 좋은 팀을 만들 수 있지 않을까 싶었어요. 점심 먹고 커피 마시면서, 같이 한번 만들어 봤으면 좋겠습니다.”
분석가가 빠진 자리에 데이터 에이전트가 들어왔습니다. 그 자리는 사람이 부족해서 비워진 자리가 아니라, 사람이 더 잘할 수 있는 일을 하기 위해 비켜 준 자리였습니다. 다음에 비워질 루프는 어디일지, 마이리얼트립의 다른 팀들이 그 답을 함께 찾고 있습니다.
*마이리얼트립의 PEPE(Product Engineer Possibility Exchange)는 PE(Product Engineer)들이 “어디까지 시도했는지, 어디서 막혔는지”를 결과보다 과정으로 나누는 사내 세션입니다.



