Spring Batch, 처음부터 시작하기
커머스 서비스 개발자를 위한 Spring Batch 입문
커머스 서비스 개발자를 위한 Spring Batch 입문
안녕하세요. 마이리얼트립 Stay & Ride 개발팀의 백엔드 개발자 정휘준입니다. 이번 글에서는 Spring Framework이 제공하는 다양한 기술 집합 중에서도, 커머스 서비스의 백엔드에 필수적인 배치 작업을 쉽고 빠르게 개발하고 관리하게 해 주는 Spring Batch에 대해 알아보고, Spring Batch를 처음 학습하고 도입할 때 겪었던 시행착오를 공유하려고 합니다.
우리나라의 많은 커머스 플랫폼들이 Java/Spring 기반 웹 서비스 위에서 운영되고 있습니다. Spring Framework는 2002년 첫 릴리즈 이후 Java 생태계에 빠르게 녹아들며 지금은 Java로 엔터프라이즈급 웹 애플리케이션을 작성하는 사실상의 기술 표준이 되었습니다.
Spring Framework을 이루는 기술 중 Spring Boot나 Spring MVC와 같은 기술은 이미 업계에 잘 알려져 있다고 생각하는데요, 이보단 다소 생소할 수도 있는 Spring Batch 프레임워크에 처음 입문하실 때 알아두시면 좋은 점들을 정리해 보겠습니다.
Spring Batch 앱을 이루는 요소들
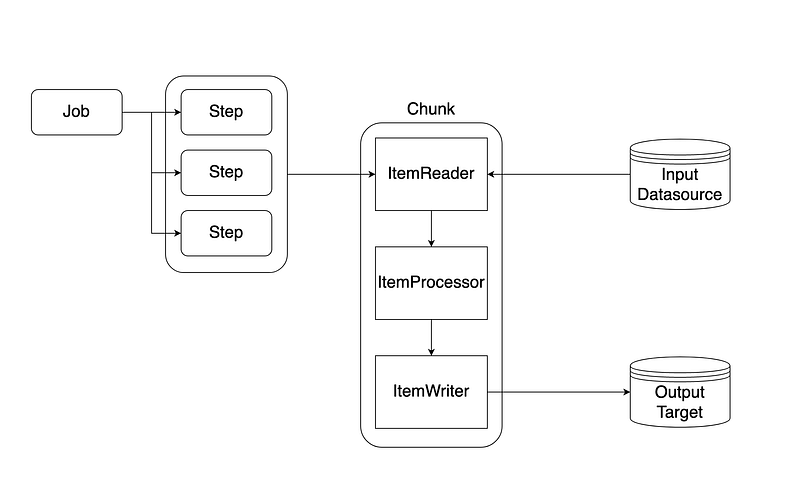
도표를 중심으로 간략하게, Spring Batch 애플리케이션을 이루는 대표적 컴포넌트들에 대해 알아보겠습니다.
Spring Batch의 코어 컴포넌트들
Job, Step
Spring Batch를 통해 작성하고 관리할 작업의 최소 단위입니다. 하나의 Job은 하나 혹은 그 이상의 Step으로 구성됩니다.
Step을 통해 개발자는 실제 작업을 통해 가공될 데이터를 읽어 들이고, 가공하고, 결과를 기록하는 로직을 묶어서 관리하게 됩니다.
Chunk?
한 번의 오퍼레이션을 통해 다룰 데이터의 집합입니다. 각 Step은 설정에 정의된 chunk 단위에 따라 데이터를 읽어 들이고, 가공한 후 기록합니다. Step의설정에서 chunk의 크기를 결정합니다. 크기의 단위는 데이터베이스의 한 row일 수도 있고, CSV 파일의 한 줄일 수도 있습니다.
데이터베이스 작업을 수반하는 Step이라면, 이 chunk는 트랜잭션의 관리단위가 되기도 합니다. 즉, 하나의 chunk를 처리하는 동안 Spring Batch는 컴포넌트 간에 계속하여 TX를 전파하고, 마지막 처리가 끝나는 시점에 TX를 커밋하거나 롤백합니다. 특히 Spring Data JPA를 사용해 Step을 구성하는 경우, chunk의 이런 속성은 영속성 컨텍스트의 생성/소멸 주기와도 관련이 있으므로 각별히 유념해야 합니다.
ItemReader, ItemProcessor, ItemWriter
- ItemReader<Input>
배치 작업의 대상이 될 데이터를 읽어 들이는 컴포넌트입니다. chunk를 통해 정의한 입력 데이터의 타입과 같은 타입의 데이터를 읽어 들이게 구현해주면 됩니다.
- ItemProcessor<Input, Output>
데이터를 비즈니스 로직에 따라 가공하고, 변경된 데이터를 리턴하는 컴포넌트입니다.
- ItemWriter<Output>
추출 및 가공이 완료된 데이터를 정해진 곳에 저장/색인합니다.
Job, JobInstance, JobExecution, StepExecution
여기에서 설명하는 요소들은 Spring Batch가 실행중이거나, 실행되었던 작업을 타당하게 추적하기 위해 사용하는 개념들입니다.
- Job
아까 설명했던 것처럼, 개발자가 설계/작성하고, 한 번에 실행되기를 의도하는 작업의 집합입니다.
- JobInstance
작업의 독립된 실행 단위입니다. 하나의 JobInstance는 고유한 JobParameter를 갖고, JobParameter는 JobInstance 객체의 동등성(equality)을 평가하는 기준이 됩니다. JobInstance에는 기본 값으로 UNIQUE 조건이 부여되므로, 원칙적으로 같은 JobParameter를 가진 두 개 이상의 JobInstance는 생성될 수 없습니다(MapJobRepository 등을 통해 우회할 수 있는 방법은 있습니다).
- JobExecution
작업의 독립된 실행 단위인 JobInstance에 대한 한 번의 실행 시도입니다. 각 Job은 재시작 여부를 결정하는 flag인 boolean restartable = false 을 갖습니다. 명시적으로 개발자가 재시작이 가능하다고 값을 명시해줬을 경우, 하나의JobInstance는 여러개의 JobExecution을 가질 수 있습니다.
- StepExecution
Job이 갖고 있던 하나의 Step에 대한 한 번의 실행 시도입니다.
—
이로써 Spring Batch의 기본 개념과 코어 컴포넌트들을 살펴 보았습니다. 다음으로는 구체적인 사례를 통해, Spring Batch 기반 배치 애플리케이션을 작성할 때 경험했던 어려움과, 미리 알았다면 좋았을 뻔한 토막 팁들을 공유해보도록 하겠습니다.
이름도 비슷한 값을 세 개나 설정해야 하다니!
한 시간에 한 번씩 마이리얼트립의 데이터베이스에 저장되어 있던 숙박 상품 정보를 가공하는 배치잡을 작성하고 있었습니다. 이 작업에선 우리의 DB에 저장되어 있는 정보들을 불러와, 외부 API를 호출해 최신 정보를 받아 상품 정보에 반영한 후, 여행자에게 더 가치있는 정보를 제공할 수 있도록 가공 작업을 마친 후 DB에 다시 업데이트하는 간단한 로직을 수행합니다.
ItemReader 의 구현체로는 JDBC Template 기반 페이징 READ를 도와주는 JdbcPagingItemReader 를 선택하였고 로직 작성 자체에는 별 어려움을 겪지 않았습니다.
그러나 처음 배치 잡을 설계하고 작성할 때, 저를 헷갈리게 한 세 가지의 설정값이 있었습니다.
@Bean
public Job dataFetchAndUpdateJob(JobBuilderFactory factory) {
return factory.get("updateJob")
.<Product, Product>chunk(500) //1...@Bean
public ItemReader<Product> jdbcProductReader(DataSource dataSource) {
return new JdbcPagingItemReaderBuilder<>()
.dataSource(dataSource)
.fetchSize(???) //2
.pageSize(???) //3...
취지가 비슷해보이는 세 가지 설정값을 각각 다른 값으로 설정할 수 있습니다!
세 가지 설정값에 차이를 두는 것이 어떤 차이를 만들지 처음엔 가늠하기 어려운데요, 이럴땐 Javadoc을 참고하는 게 가장 좋을 것 같습니다.
우선 JdbcPagingItemReaderBuilder 의 Javadoc을 확인하겠습니다.
fetchSize: A hint to the underlying RDBMS as to how many records to return with each fetch.
pageSize: The number of records to request per page/query.
Javadoc을 통해 살펴보면, fetch size는 RDBMS에게 몇 개의 result row를 준비해야할지 알려주는 설정값이 됩니다. page size 설정은, 실제로 배치 프로세싱 과정 중에 한 페이지로 간주할 result row의 개수입니다.
앞서 우리는 Spring Batch의기본 개념을 살펴보면서, chunk 란 스프링 배치를 통해 처리될 정보들의 최소 단위 라는 점을 알게 되었습니다. 또한, chunk 단위로 트랜잭션이 전파/커밋/롤백된다는 사실 또한 알고 있습니다. 결국, chunk 와 pageSize 의 이상적인 절대값은 존재하지 않고, 개발중인 시나리오에 맞춰 최적해를 찾아나가야 하겠지만, 적어도 두 값이 가급적 동일하게 부여되는 것이 좋다는 합리적인 추론에는 무리없이 도달할 수 있습니다.
단순한 추천이 아니라, 잘못 설정된 값으로 인해 예외 상황을 맞는 경우도 있습니다. JPA 기반 ItemReader/ItemWriter를 사용하는 배치 애플리케이션에서, pageSize 와 chunk 의 값이 다르면 어떤 상황이 벌어질 수 있을지 아래 도표를 통해 살펴보겠습니다.
JPA 기반 스프링 배치 애플리케이션을 작성할 때 JPA의 Persistence Context, 혹은 EntityManager 또한 chunk 단위로 생성되고 전파됩니다. 위 그림은 Spring Batch 애플리케이션에서 애플리케이션의 각 컴포넌트와 chunk , 그리고 EntityManager 의 관계를 도식화한 것입니다.
EntityManager 는 하나의 청크에 해당하는 정보들을 온전히 처리하고 다음 청크를 읽어 들일 때까지 애플리케이션 컨텍스트에 생존하며, JPA가 제공하는 lazy loading, dirty check와 같은 기능을 온전하게 제공합니다.
만약 pageSize 가 chunk 값과 달라 읽어 들인 한 페이지를 처리하기도 전에 영속성 컨텍스트가 소멸한다면, 소멸 이후 읽혀진 객체들의 경우, 이미 JPA 세션이 닫혔기 때문에 LazyInitializationException 이 발생합니다(이 상황에 대한 더 깊은 설명은 여기를 참고해 주세요).
데이터베이스 커넥션 누수가 탐지되는 경우
배치 애플리케이션이 아닌 일반적인 웹 앱에서도 충분히 재현될 수 있는 상황이지만, 배치 애플리케이션에서는 유난히 DBCP connection leak을 경고하는 콘솔 메세지가 자주 출력됩니다.
실제로 커넥션 풀이 고갈되어 애플리케이션을 멈추게 할 상황이라면 로직 수정이 필요하겠지만, 대부분의 경우 오탐지인 사례가 많아 즉각적인 장애 대응이 필요하지는 않은 상황인 경우가 많습니다.
하지만 어떤 상황에서도 애플리케이션 로직이 하나의 커넥션을 지나치게 오래 점유하는 것은 바람직한 상황은 아닙니다. 제가 배치 작업을 작성하며 겪었던 상황을 간단히 공유하고, 어떤 해결책을 선택할 수 있을지 정리해 보겠습니다. 들어가기에 앞서, 저는 DBCP 구현체로 Hikari CP를 택하고 있음을 밝혀둡니다.
@Bean
public ItemProcessor<Product, Product> productUpdateProcessor(RestTemplate restTemplate) {
return product -> {
Product newProduct = restTemplate.getForObject(...);
if(newProduct == null) {
return null;
} product.reflectNewInfos(newProduct);
return product; };
외부 API를 호출해 최신정보를 받아오고, 이를 이미 저장되어있던 객체에 반영하는 간단한 로직이지만 언제든지 외부 API는 느려질 수 있다는 간단한 진리를 무시하고 설계했다는 것을, 얼마 지나지 않아 알게 되었습니다.
2020-08-01 10:21:16.252 WARN 924 --- [l-1 housekeeper] com.zaxxer.hikari.pool.ProxyLeakTask : Connection leak detection triggered for com.mysql.jdbc.JDBC4Connection@ffd3737 on thread http-nio-80-exec-8, stack trace follows
java.lang.Exception: Apparent connection leak detected
at com.zaxxer.hikari.HikariDataSource.getConnection(HikariDataSource.java:128) ~[HikariCP-2.7.9.jar:na]
at org.hibernate.engine.jdbc.connections.internal.DatasourceConnectionProviderImpl.getConnection(DatasourceConnectionProviderImpl.java:122) ~[hibernate-core-5.2.17.Final.jar:5.2.17.Final] ...
이와 같은 에러 메세지가 chunk 하나를 쳐낼 때마다 뿜어져나왔던 것입니다.
1) 청크 사이즈를 줄여보자
배치 앱이 chunk 단위로 트랜잭션을 전파한다는 속성에 착안하여, 하나의 트랜잭션으로 처리될 chunk의 크기를 줄이면 문제가 해결된다는 가설을 세웠습니다. 데이터베이스 관련 로직의 볼륨이 크지 않고, 배치 앱이 구동될 인스턴스의 가용 RAM도 충분하여 chunk size를 다소 크게 설정했는데 이를 줄여보았습니다. 앞서 pageSize 와 chunk 의 값이 다를 때 어떤 사이드 이펙트가 발생할 수 있는지 확인하였습니다. 가설검증을 위해 chunk size를 지속적으로 조금씩 변경할 필요가 있을 것 같아, configuration 클래스의 상단에 chunk size를 상수로 선언하고 StepBuilder 와 ItemReaderBuilder 에 각각 부여하였습니다.
private static final int DEFAULT_CHUNK_SIZE = 50;@Bean
public Step productUpdateStep(StepBuilderFactory factory) {
return factory.get("productUpdateStep")
.<Product, Product>chunk(DEFAULT_CHUNK_SIZE)
...
@Bean
public ItemReader<Product> productReader(DataSource dataSource) {
return new JpaPagingItemReaderBuilder<>()
.dataSource(dataSource)
.pageSize(DEFAULT_CHUNK_SIZE)...
몇 번의 실험 끝에 최적의 chunk/page size를 발견할 수 있었고. Hikari는 잠잠해 졌습니다.
2) HikariCP의 누수 탐지값을 조정한다
개발자의 판단으로 봤을 때, connection leak에서 안전한 로직을 작성했다고 생각되는 경우, 아래 설정값을 조절하여 충분한 누수 탐지 시간을 벌어줄 수 있습니다.
spring.datasource.hikari.leakDetectionThreshold = 5000
단위는 millis이며, 0으로 부여하면 탐지하지 않는 것이 Hikari CP의기본 작동이지만 Spring Autoconfiguration으로 주입받은 커넥션 풀을 사용하는 경우, 설정값에 0을 부여했다면 자동으로 애플리케이션 컨텍스트가 2000으로 값을 조정합니다.
마치며
Spring Batch를 사용하여 커머스 플랫폼 개발에 꼭 필요한 배치 작업 작성을 쉽고 빠르게 진행하는 방법을 알아보았습니다. “입문기" 이므로 꼭 알고 시작해야 할 내용들을 다루는 데에 집중했는데요, 어떤 분들께는 너무 쉽고 당연한 내용이었을지도 모르겠습니다.
마이리얼트립의 백엔드 개발자들은 Spring Batch 기반으로 작성한 수백 개의 배치잡을 관리하며 국내최고의 Travel Super App, 마이리얼트립을 뒷받침하는 플랫폼을 만들고 있습니다.
효율적인 배치 작업의 작성 외에도, 우리는 수많은 도전적인 개발 과제들을 날마다 마주하고, 또 해결합니다. 저희와 함께 여행을 혁신하는 기술 과제들을 경험해보고 싶으신 분들은 아래의 채용 페이지를 방문해 주시기 바랍니다.



